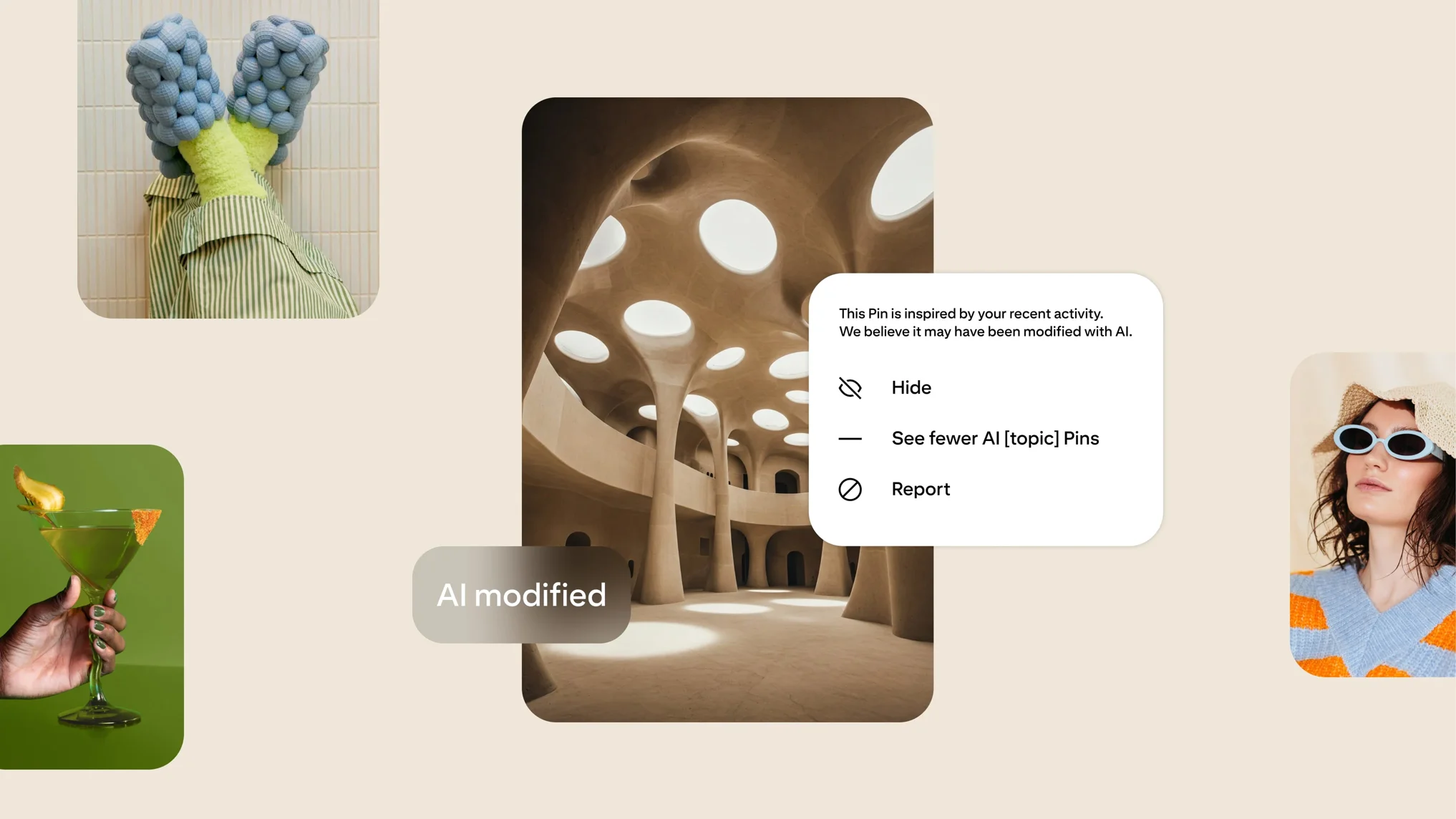
Pinterest is developing an AI text-to-image generation process called "Canvas" to enhance product shot backgrounds without altering the main product. This system isolates the background and foreground using a segmentation model to generate product masks. The AI is trained on a curated set of images to align with specific visual styles, allowing brands to create varied and appealing product visuals.
Building Pinterest Canvas
Pinterest Canvas is a text-to-image model that supports arbitrary conditioning information in the form of product masks and conditioning images for stylistic guidance. The model is built as a latent diffusion model trained exclusively in-house at Pinterest. It operates in the latent space learned by a variational autoencoder (VAE). Text captions are encoded using both CLIP-ViT/L and OpenCLIP-ViT/G and are fed to a convolutional UNet via cross-attention to incorporate text conditioning information during the generation process.
During training, random caption-image pairs are sampled from a dataset, encoded into latent representations using VAE, and embedded using CLIP. Noise is added to each image latent, and the UNet is tasked with denoising the latent given the text embedding and timestep index. The training data is filtered to ensure high quality, trust, and safety standards, resulting in over 1.5 billion high-quality text-image pairs.
Fine-tuning for Background Generation
Pinterest Canvas is fine-tuned to perform specific visualization tasks like inpainting. The model is trained in two stages:
- First Stage: Uses the same dataset as the base model and generates random masks for inpainting during training.
- Second Stage: Focuses on product images, using a segmentation model to generate product masks and incorporating more complete and detailed captions from a visual LLM. This stage involves training a LoRA on all UNet layers for rapid, parameter-efficient fine-tuning.
The model can take a product Pin and generate a background according to a text prompt. The VAE is retrained to accept additional conditioning inputs to seamlessly blend the original and generated image content, ensuring pixel-perfect reconstructions of products. Multiple variations are generated, and the top k are selected using a reward model trained on human judgments.
Personalizing Results
To further enhance personalization, the model is augmented to condition on other images, using their style to guide the generation process. This is achieved by building off of IP-Adapter, which processes additional image prompts within the diffusion UNet. These prompts are encoded into embeddings and passed alongside text embeddings to new image-specific cross-attention layers.
For personalization, stylistic context is appended in the form of concatenated UVE and CLIP embeddings. Different ways of collecting conditioning images are experimented with, including using boards with strong styles and automatically mining style clusters. Using Pinterest's internally developed Unified Visual Embedding (UVE) generally leads to a stronger effect on the resulting generations.