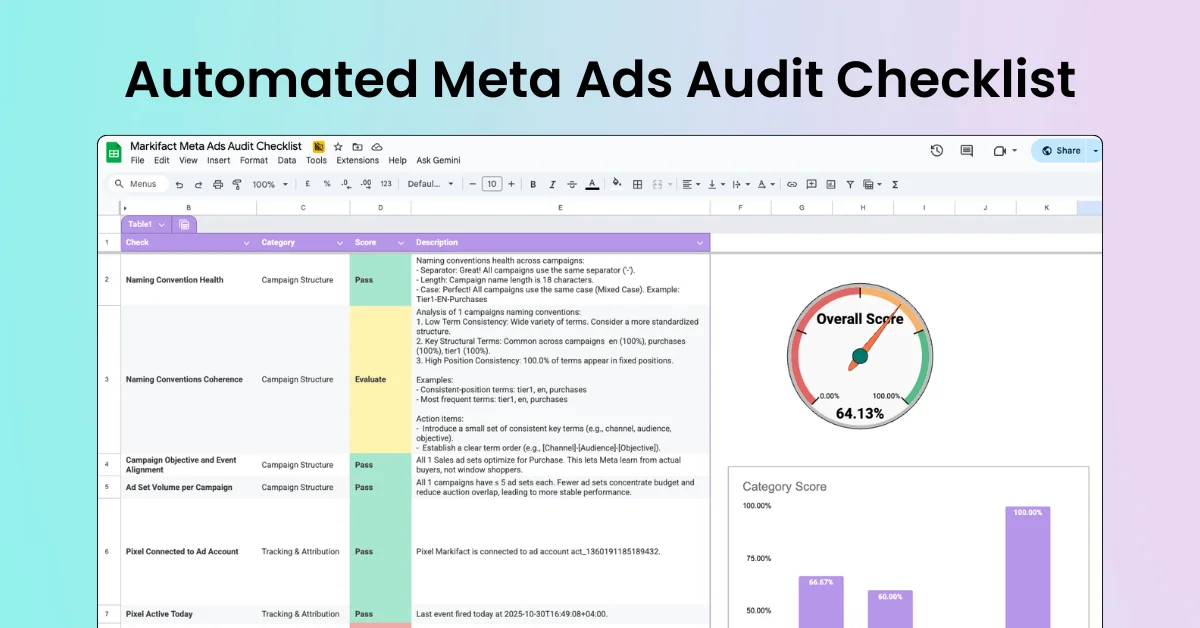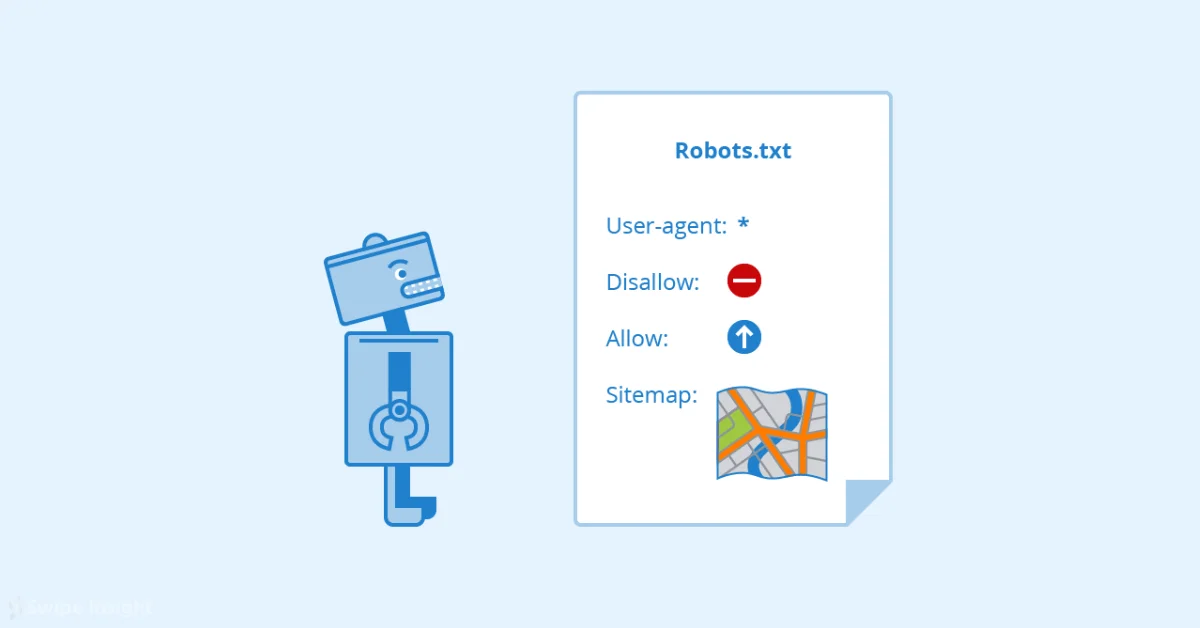
Gary Illyes, an analyst at Google, has recently addressed a common misconception about the capabilities of robots.txt files in controlling access to web content.
Key Points from Illyes' Statement
robots.txt Limitations: Illyes confirms that robots.txt cannot prevent unauthorized access to content, contrary to some recent discussions.
Proper Access Control: For true access authorization, websites need systems that authenticate requestors and control access, such as:
- Firewalls (IP-based authentication)
- Web servers (HTTP Auth or SSL/TLS client certificates)
- Content Management Systems (username/password and cookies)
robots.txt Function: Illyes likens robots.txt to "lane control stanchions at airports" - a guideline rather than a strict barrier.
Appropriate Tools: He emphasizes the importance of using proper tools for access control, stating there are "plenty" available.
Implications for Webmasters
This clarification is crucial for webmasters and SEO professionals who might be relying on robots.txt for content protection. Illyes' post serves as a reminder to implement robust access control measures for sensitive content, rather than depending solely on robots.txt directives.
Conclusion
Illyes concludes with a clear message: while robots.txt has its place in web management, it should not be considered a form of access authorization. Webmasters should utilize appropriate tools and methods to secure and control access to their content effectively.