Google has updated its googlebot.json file, which contains the IP addresses used by Googlebot, from weekly to daily based on community feedback. Gary Illyes stated that website administrators and SEO professionals may need to adjust their systems. This change aims to help organizations better manage their interactions with Google's crawling infrastructure and improve the identification of legitimate Googlebot activity.
Google's Search Relations team warns about unintended URL proliferation in website management. URLs can have infinite parameters, causing multiple URLs to point to the same content, confusing search engines, and straining servers due to excessive crawler activity. Bad relative links often cause this. Google recommends using robots.txt to manage URL parameters and suggests webmasters audit their site's URL structure.
Google's Gary Illyes discussed SSL/TLS and mutual TLS (mTLS), emphasizing their roles in secure web communications and web crawling. Traditional TLS focuses on server authentication, keeping the client anonymous, and is sufficient for most applications. mTLS authenticates both client and server, enhancing security in zero-trust environments. This is useful for API endpoint security and web crawling from shared IP ranges. Google may consider using mTLS in its web crawling operations.
Google Alerts remains relevant and effective, offering email notifications, customizable searches, and real-time monitoring. It serves various purposes, from security monitoring to competitor tracking. Gary Illyes from Google's Search Relations team shared a real-world example of detecting a hack using Google Alerts. Despite new tools, Google Alerts is still a valuable, free resource for webmasters and SEO professionals.
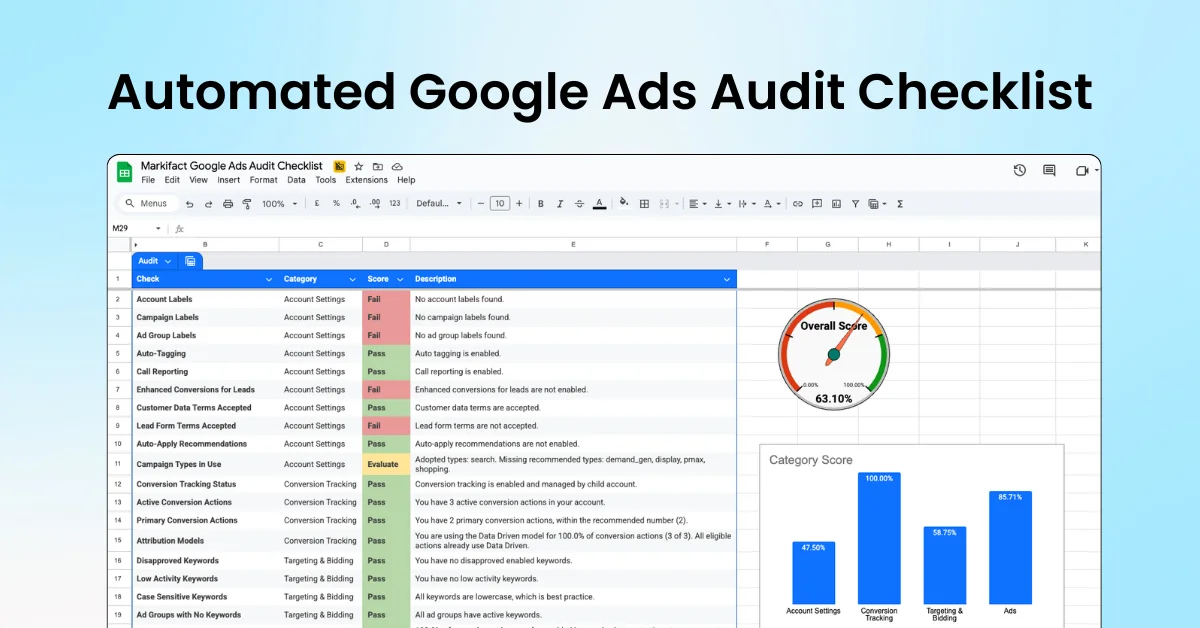
Run an automated Google Ads audit directly from Google Sheets with 40+ built-in checks. Review campaigns, ad groups, keywords, ads, and account settings to catch missed best practices and optimization gaps. Ideal for agencies and in-house teams to standardize audits, save hours of manual work, and turn findings into clear, actionable recommendations.
Gary Illyes, a Google analyst, clarified that robots.txt cannot prevent unauthorized access to web content. True access control requires systems like firewalls, web servers, and content management systems. Illyes compared robots.txt to "lane control stanchions at airports," emphasizing it as a guideline, not a barrier. He urged webmasters to use proper tools for access control and not rely solely on robots.txt for content protection.
Google’s Gary Illyes warned against relying solely on AI-generated answers, stressing the need to verify information with authoritative sources. He noted that while Large Language Models (LLMs) produce contextually relevant responses, they are not always factually accurate. Illyes mentioned "grounding" as a technique to improve accuracy but emphasized it’s not foolproof. Users should validate AI responses with personal knowledge and trusted resources to avoid misinformation.
Google challenges the belief that a website's robots.txt file must be at the root domain. Websites can use a centralized robots.txt file hosted on a different domain, such as a CDN. Webmasters can redirect their main domain's robots.txt to this CDN-hosted version, and compliant crawlers will follow the redirect. This offers more flexibility, especially for those using CDNs. The possibility of future changes regarding the file's name was also hinted at.
robots.txt is 30 years old and is virtually error-free because parsers ignore mistakes, ensuring they don't crash. ASCII art or misspelled directives like "disallow" are ignored, which might be unfortunate but doesn't affect the rest of the file. Anything unrecognized by the parser, such as user-agent, allow, and disallow, is ignored, leaving the rest usable. The author questions the need for line comments and invites readers to share their thoughts.
Soft 404s and other hidden errors are problematic for web crawlers. When a page returns an HTTP 200 status code despite being an error, crawlers repeatedly visit it, wasting resources that could be used on valuable content. This misuse of the "crawl budget" means fewer real pages are indexed, reducing their visibility in search results. Always serve the correct HTTP status code for errors to help crawlers efficiently index your site.