Google Search boosts thrift and vintage shopping with AI tools
4 days ago
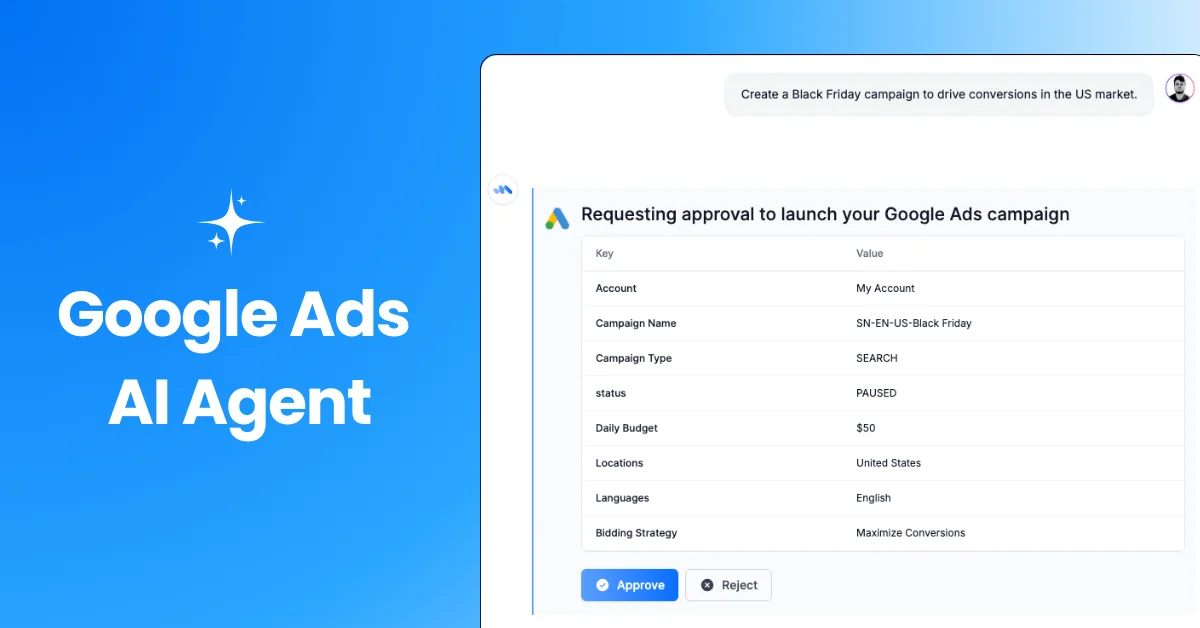
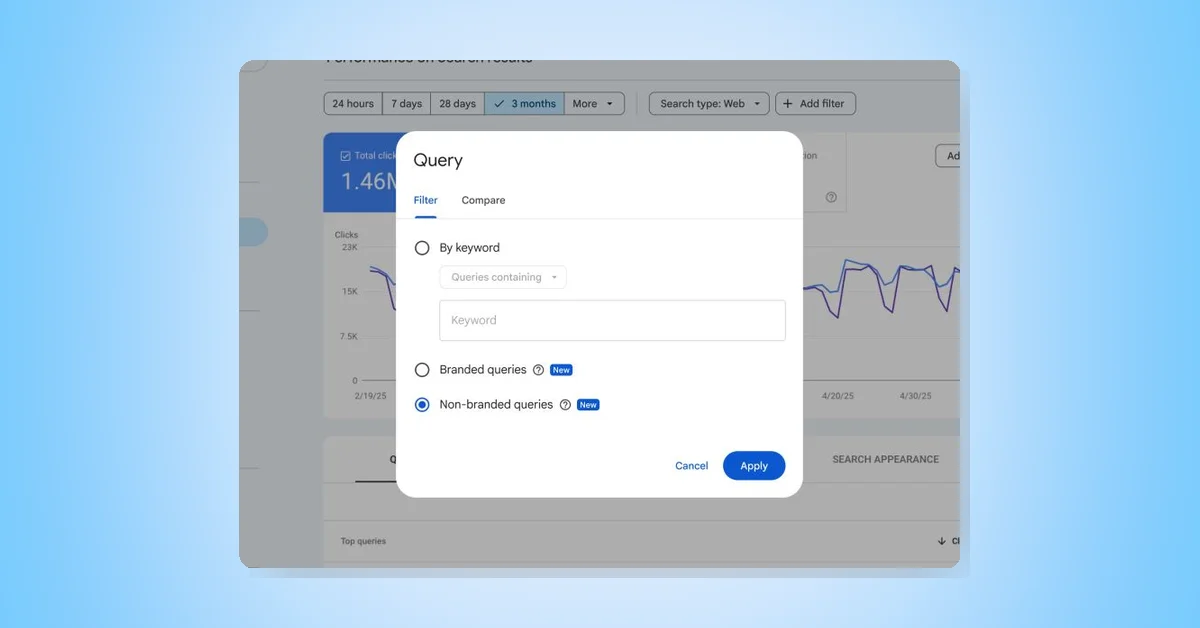
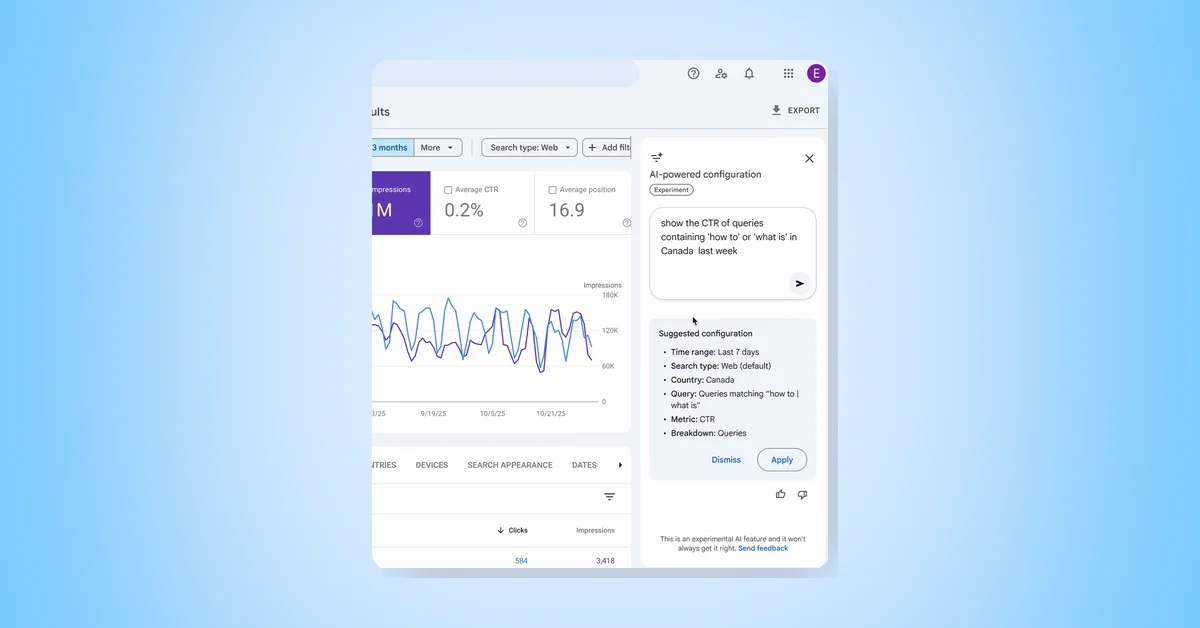
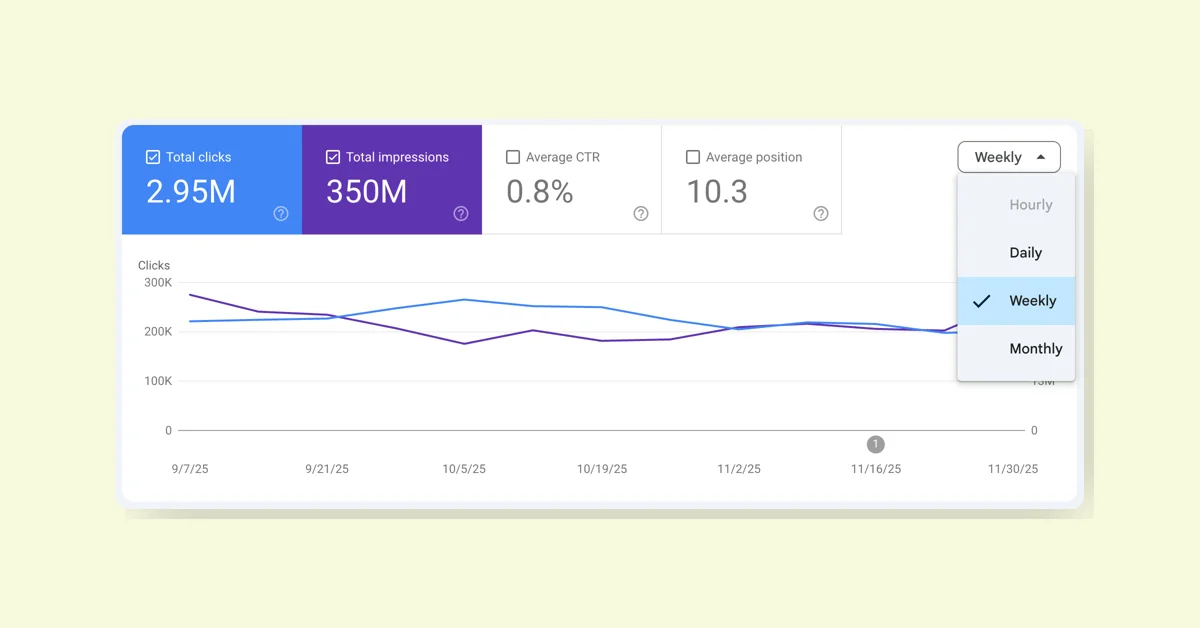
With rising interest in vintage and thrifting, Google Search offers AI tools to enhance the experience. AI Mode helps plan thrift trips with specific queries, Google Lens identifies and values items in stores, Circle to Search finds similar online products, Virtual Try-On lets users try styles digitally, and Lens also assists in valuing items for resale, making thrifting easier and more interactive.