Summary
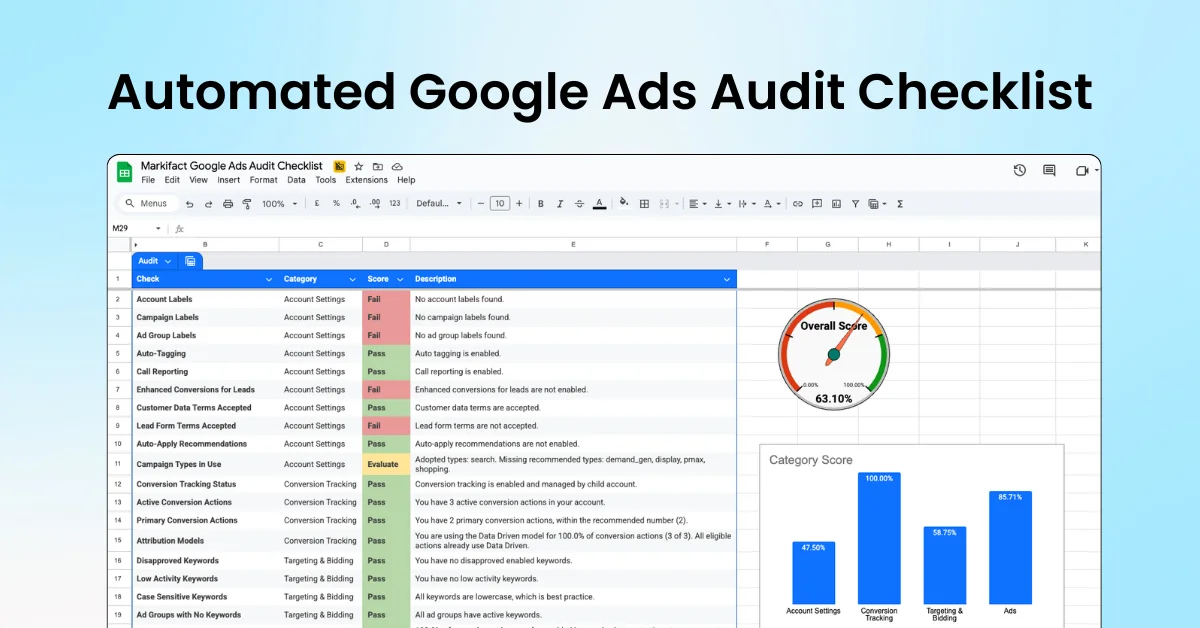
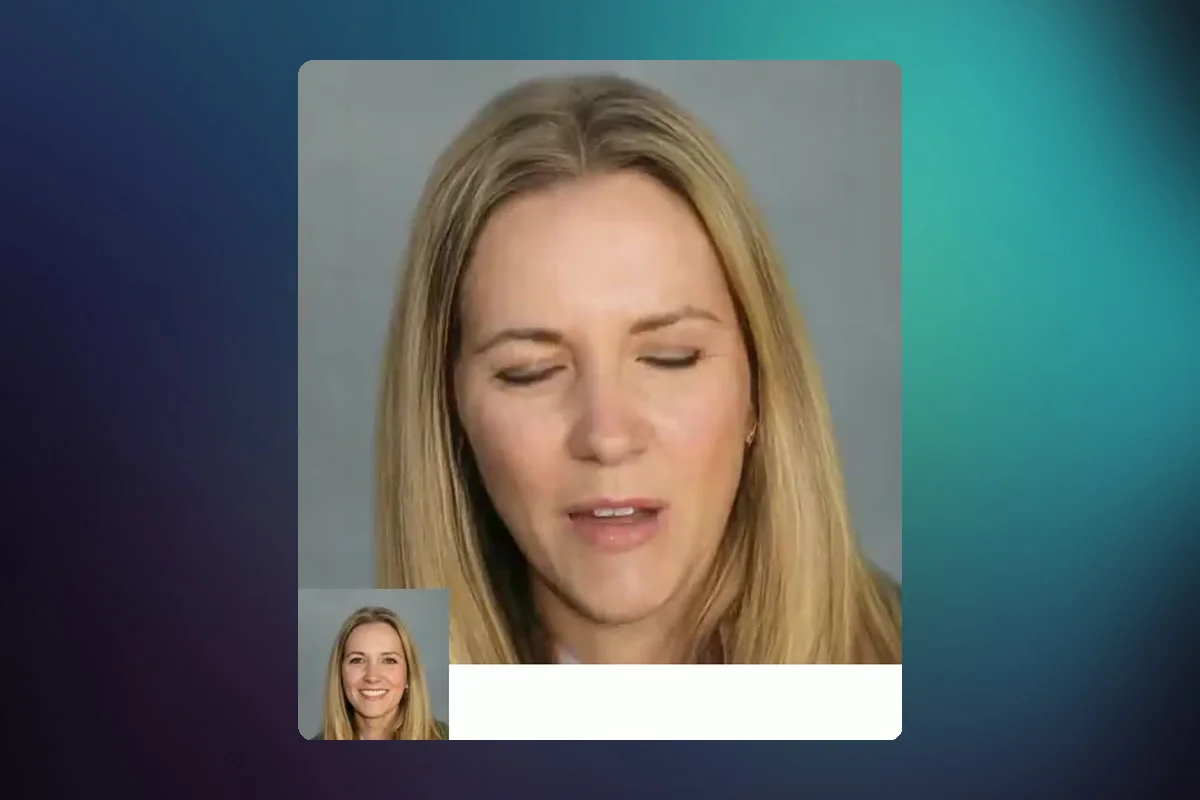
Microsoft's latest VASA-1 model can create hyper-realistic deepfakes from an image in 170 milliseconds. It uses audio for lifelike facial behavior and real-time head movements. The model provides videos at 512x512 resolution and up to 40 FPS, with a 170-millisecond latency on NVIDIA RTX 4090 GPU systems. VASA-1 uses a diffusion-based model for comprehensive facial dynamics and head movements.