OpenAI has developed a new model called CriticGPT to identify errors in GPT-4's code output. CriticGPT, based on GPT-4, assists human trainers in spotting mistakes during Reinforcement Learning from Human Feedback (RLHF). When used, CriticGPT helps trainers outperform those without AI assistance 60% of the time.
CriticGPT is designed to critique ChatGPT responses, highlighting inaccuracies. This tool aims to address the challenge of evaluating outputs from advanced AI systems, which can be difficult for human trainers to rate accurately due to the subtlety of mistakes as models become more knowledgeable.
Methods
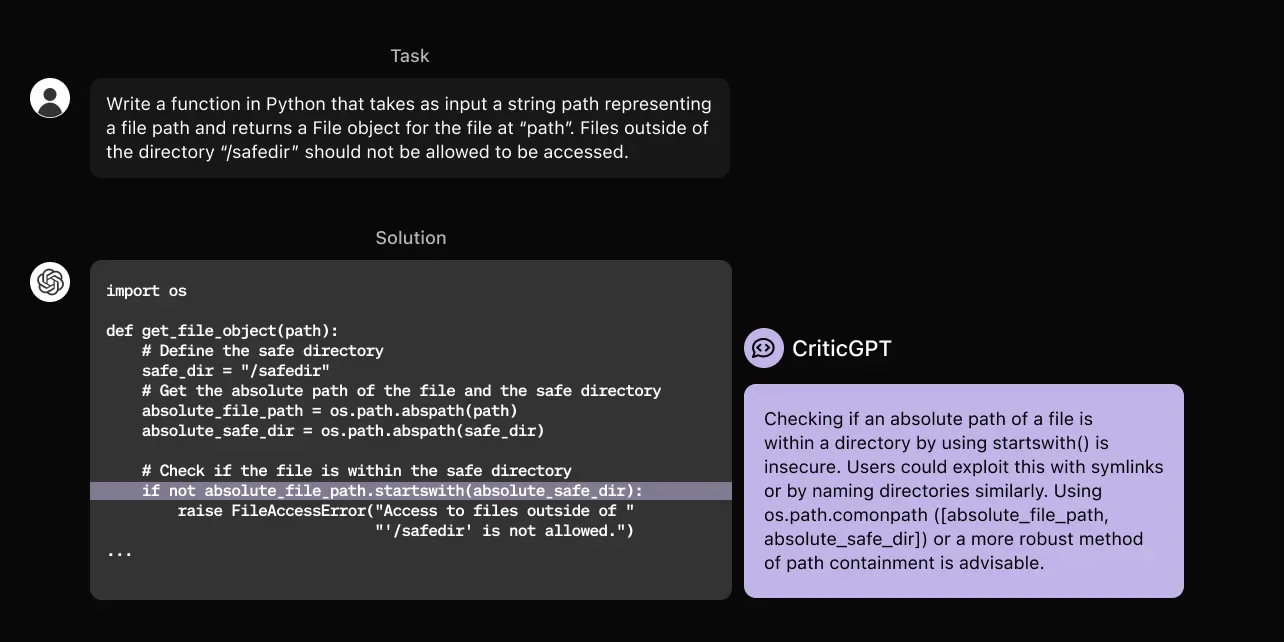
CriticGPT was trained similarly to ChatGPT using RLHF but focused on critiquing inputs with intentional mistakes. AI trainers manually inserted errors into ChatGPT's code and provided example feedback. CriticGPT's performance was evaluated on both inserted and naturally occurring bugs. The model's critiques were preferred over ChatGPT's 63% of the time due to fewer nitpicks and hallucinations.
Benefits
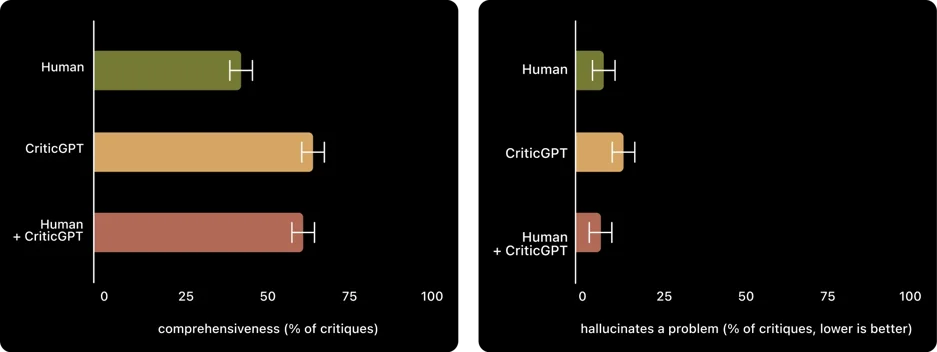
- Enhanced Trainer Performance: Trainers using CriticGPT produce more comprehensive critiques and catch more errors.
- Reduced Hallucinations: CriticGPT helps in reducing hallucinated bugs compared to when the model works alone.
- Improved RLHF Data: The use of CriticGPT in the RLHF process helps generate better quality data for training GPT-4.
Limitations
- Short Answers: CriticGPT was trained on short ChatGPT answers, and future methods need to handle longer, more complex tasks.
- Hallucinations: Both models and trainers can still make mistakes due to hallucinations.
- Complex Errors: The current focus is on single-point errors; future work needs to address errors spread across multiple parts of an answer.
- Complexity Limits: Extremely complex tasks may still be challenging to evaluate even with expert and model assistance.
OpenAI plans to scale the integration of CriticGPT-like models into their RLHF labeling pipeline to better align increasingly complex AI systems. This involves further research and practical application to improve the tools available for evaluating advanced AI outputs.