Google has released new insights into how Googlebot crawls websites, detailing the intricacies of its web crawling process in a recent Search Central update published on December 3, 2024.
Google explains that crawling is the initial step before pages appear in search results. Through Googlebot, their server-based program, Google retrieves URLs while managing network errors, redirects, and other technical complexities encountered during web navigation.
Googlebot's Modern Resource Handling
Google revealed their exact process for handling modern web resources:
The crawling system follows a four-step process:
- Googlebot downloads the page's HTML
- The content is transferred to the Web Rendering Service (WRS)
- WRS utilizes Googlebot to retrieve referenced resources
- The page is constructed using all downloaded components
Resource Management and Crawl Budget
Google disclosed that their WRS caches resources for up to 30 days, independent of HTTP caching directives. This caching mechanism helps preserve a site's crawl budget for other essential crawling tasks. Google provided several practical recommendations for managing crawl budget effectively:
Optimize resource usage by minimizing necessary files while maintaining user experience quality. They suggest hosting resources on separate domains or CDNs to distribute crawl budget impact across different hostnames.
The company emphasizes careful consideration when using cache-busting parameters, as URL changes may trigger new crawls even when content remains unchanged.
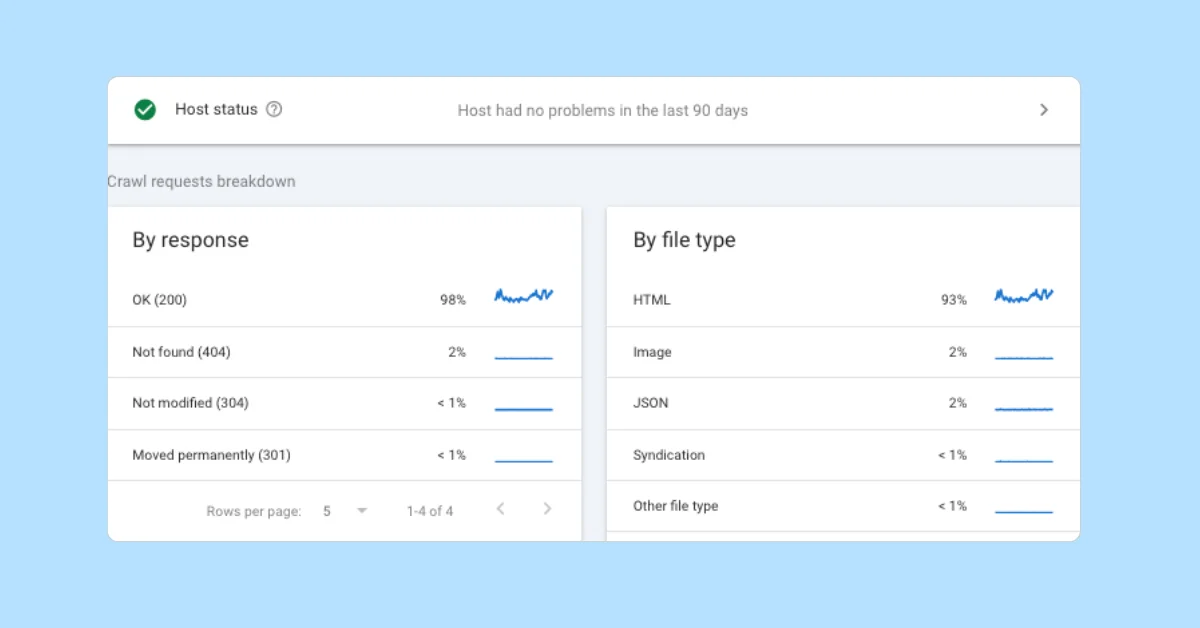
Monitoring Tools
Google confirmed two primary methods for tracking Googlebot activity:
- Server access logs for comprehensive URL request data
- The Search Console Crawl Stats report for detailed crawler-specific insights
Google notes that while robots.txt can control crawling, blocking rendering-critical resources may impair their ability to properly index and rank pages in search results.