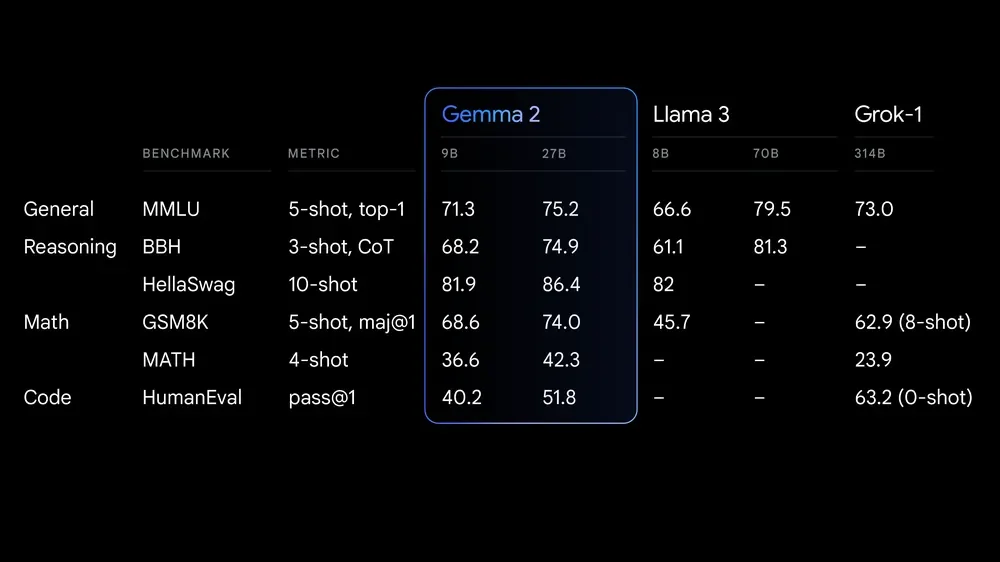
Google is releasing Gemma 2, an open lightweight model series, to researchers and developers through Vertex AI next month. Initially, Gemma 2 includes models with 9 billion (9B) and 27 billion (27B) parameters. These models are built on a redesigned architecture, offering high performance and efficiency, with significant safety advancements.
Key Features of Gemma 2
- Performance: The 27B model offers competitive performance against models twice its size, while the 9B model outperforms others in its category.
- Efficiency: Both models are designed for cost-effective deployment, running efficiently on a single NVIDIA H100 Tensor Core GPU or TPU host.
- Speed: Optimized for fast inference across various hardware setups, from gaming laptops to cloud-based systems.
Accessibility and Integration
- Open and Accessible: Available under a commercially-friendly license, Gemma 2 supports major AI frameworks like Hugging Face Transformers, JAX, PyTorch, and TensorFlow.
- Deployment: Google Cloud customers can deploy and manage Gemma 2 on Vertex AI starting next month.
- Tools and Resources: The Gemma Cookbook provides practical examples and recipes for building applications and fine-tuning models.
Future Developments
- Upcoming Models: A 2.6B parameter Gemma 2 model is in development to balance accessibility and performance.
- Availability: Gemma 2 is accessible through Google AI Studio, Kaggle, and Hugging Face Models. Free access is available for research and development, with credits for academic researchers.
Gemma 2 aims to democratize AI development by providing powerful, efficient, and accessible models to the global research and developer community.