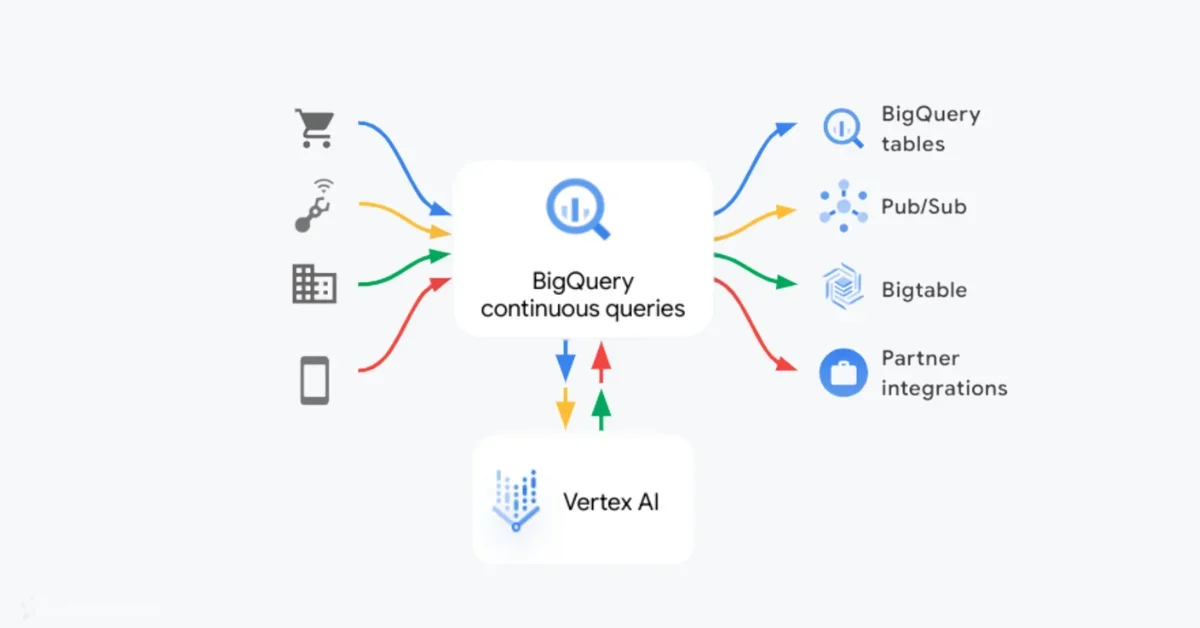
Google has announced that continuous queries in BigQuery are now generally available (GA). This feature enables users to build long-lived, continuously processing SQL statements that can analyze, process, and perform machine learning (ML) inference on incoming data in BigQuery in real time.
Continuous queries are SQL statements that run continuously, allowing users to analyze incoming data in BigQuery as it arrives. The output rows produced by these queries can be inserted into a BigQuery table or exported to Pub/Sub or Bigtable.
The system can process data written to standard BigQuery tables through various methods including:
- The BigQuery Storage Write API
- The
tabledata.insertAllmethod - Batch load operations
- The
INSERTDML statement
For monitoring purposes, users can utilize a custom job ID prefix to simplify filtering or view metrics specific to continuous queries in Cloud Monitoring. Additionally, continuous queries support slot autoscaling to dynamically adjust allocated capacity based on workload demands.
Key Applications for Continuous Queries
Google highlights several common use cases where continuous queries provide significant value:
Personalized customer interaction services allow businesses to leverage generative AI for creating tailored messages customized for each customer interaction.
For security operations, anomaly detection capabilities enable solutions that perform anomaly and threat detection on complex data in real time, helping organizations react to issues more quickly.
The customizable event-driven pipelines feature utilizes continuous query integration with Pub/Sub to trigger downstream applications based on incoming data.
Organizations can implement data enrichment and entity extraction using continuous queries to perform real-time data enrichment and transformation through SQL functions and ML models.
Reverse extract-transform-load (ETL) processes can be established to perform real-time reverse ETL into other storage systems better suited for low-latency application serving.
These capabilities position BigQuery as an event-driven data processing engine for application decision logic, enabling time-sensitive tasks such as creating and immediately acting on insights, applying real-time ML inference, and replicating data into other platforms.
Cross-Regional Federated Queries for Spanner
In a separate update, Google announced that Spanner now supports cross-regional federated queries from BigQuery. This preview feature allows BigQuery users to query Spanner tables from regions other than their BigQuery region.
During the preview period, users won't incur Spanner network egress charges when using this functionality.