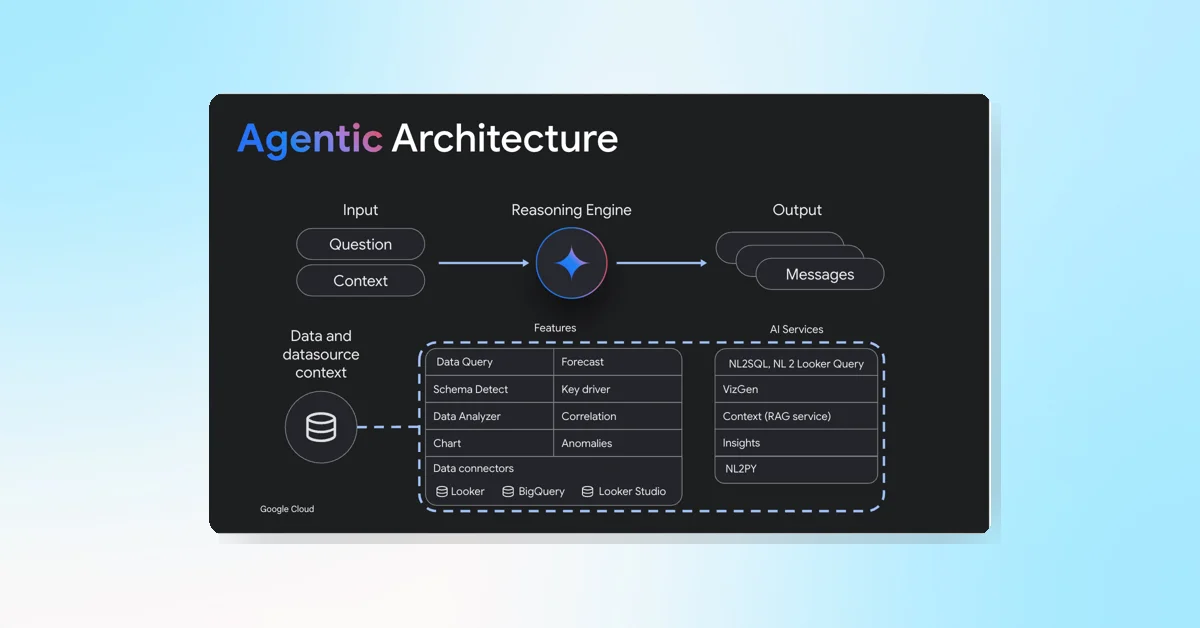
The BigQuery update introduces the DISTINCT pipe operator, now generally available (GA), which allows selecting distinct rows from a table within pipe syntax queries. This operator returns distinct rows based on all visible columns, ignoring pseudo-columns, and preserves table aliases from the input.
Key Features of DISTINCT Pipe Operator
- Can be applied anywhere in the pipe syntax, unlike traditional
SELECT DISTINCTorUNION DISTINCTwhich are limited to specific clauses. - Computes distinct rows based on all visible columns.
- Ignores pseudo-columns when computing distinct rows and excludes them from the output.
- Similar to using
|> SELECT DISTINCT *, but it does not expand value table fields and keeps table aliases intact.
Example Usage
A query with multiple rows, including duplicates, uses the |> DISTINCT operator to filter unique rows and then applies a WHERE clause to select rows where sales are greater than or equal to 3:
(
SELECT 'apples' AS item, 2 AS sales
UNION ALL
SELECT 'bananas' AS item, 5 AS sales
UNION ALL
SELECT 'bananas' AS item, 5 AS sales
UNION ALL
SELECT 'carrots' AS item, 8 AS sales
)
|> DISTINCT
|> WHERE sales >= 3;
The result returns distinct rows for "bananas" and "carrots" with sales values 5 and 8 respectively.