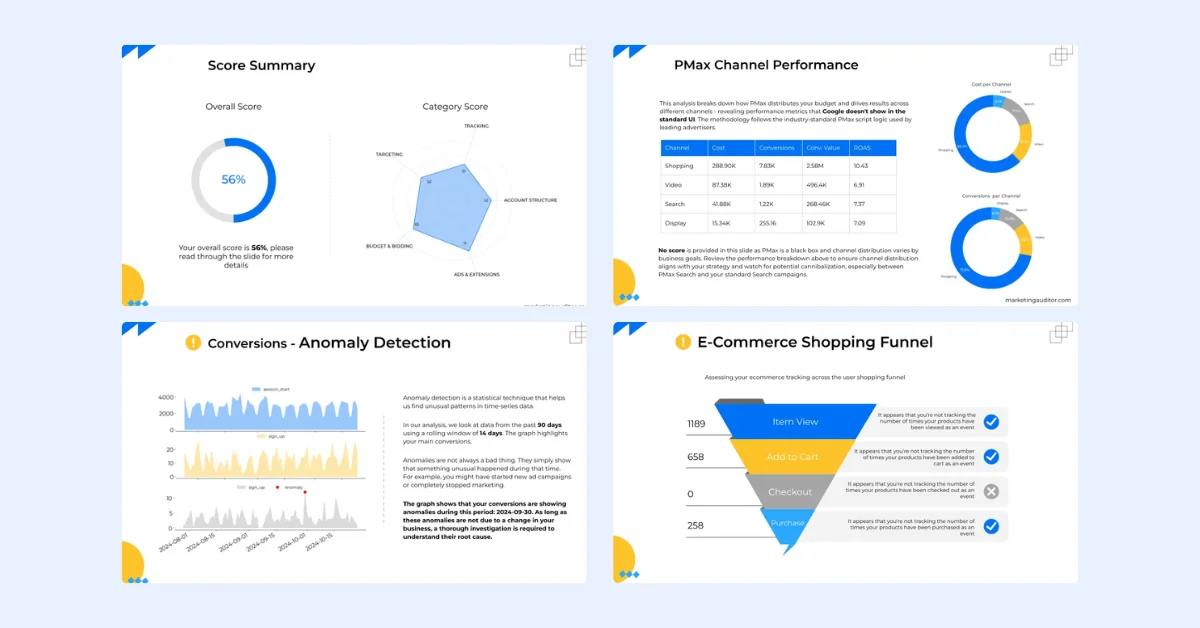
Meta and Google researchers, along with collaborators from INRIA and Université Paris Saclay, have introduced a new technique for automatically curating high-quality datasets for self-supervised learning (SSL). This method leverages embedding models and clustering algorithms to create large, diverse, and balanced datasets without manual annotation.
Balanced Datasets in Self-Supervised Learning
Self-supervised learning, which trains models on unlabeled data, is crucial for modern AI applications such as large language models and visual encoders. However, the quality of the datasets is critical for the performance of SSL models. Randomly assembled datasets from the internet often have skewed distributions, leading to biases in the models.
The researchers emphasize that datasets for SSL should be large, diverse, and balanced. Manual curation, though less time-consuming than labeling, remains a bottleneck in scaling model training.
Automatic Dataset Curation
The proposed automatic curation technique involves:
- Feature Extraction: A model computes embeddings, which are numerical representations of the semantic and conceptual features of the data.
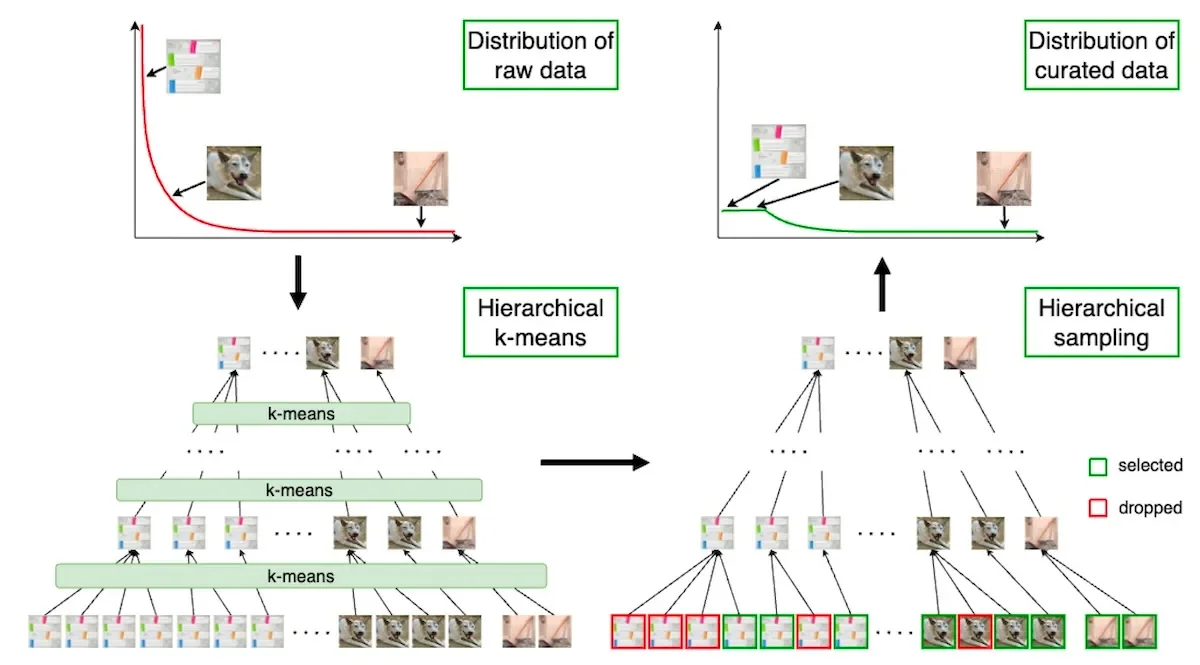
- Clustering: Using k-means clustering, data points are grouped based on similarities. However, traditional k-means clustering tends to over-represent dominant concepts.
- Hierarchical Clustering: A multi-step hierarchical k-means approach is applied to create balanced clusters. This method builds a tree of data clusters in a bottom-up manner, ensuring well-represented concepts at each level.
This technique is described as a "generic curation algorithm agnostic to downstream tasks," capable of inferring interesting properties from uncurated data sources.
Evaluating Auto-Curated Datasets
The researchers conducted extensive experiments on computer vision models trained on datasets curated with hierarchical clustering. Key findings include:
- Improved performance on image classification benchmarks, especially on out-of-distribution examples.
- Better performance on retrieval benchmarks.
- Models trained on automatically curated datasets performed nearly on par with those trained on manually curated datasets.
The algorithm was also applied to text data and satellite imagery, leading to significant improvements across all benchmarks. Models trained on well-balanced datasets could compete with state-of-the-art models while using fewer examples.
Implications
The automatic dataset curation technique has significant implications for applied machine learning projects, particularly in industries where labeled and curated data is scarce. It can reduce the costs associated with annotation and manual curation, making model training more scalable and efficient. This method could be especially beneficial for large companies like Meta and Google, which possess vast amounts of raw data.
The researchers believe that automatic dataset curation will become increasingly important in future training pipelines.