The introduction of Claude 4 brings two advanced AI models: Claude Opus 4 and Claude Sonnet 4, which set new benchmarks in coding, advanced reasoning, and AI agent capabilities. Claude Opus 4 is recognized as the world’s best coding model, excelling in sustained performance on complex, long-running tasks and agent workflows. Claude Sonnet 4 is a major upgrade over Sonnet 3.7, offering superior coding and reasoning with more precise instruction following.
Key Features and Announcements
Both models support extended thinking with tool use (beta), enabling them to alternate between reasoning and using tools like web search to enhance responses. They can also use tools in parallel, follow instructions more accurately, and demonstrate improved memory capabilities when given access to local files, allowing them to extract and save key facts to maintain continuity and build tacit knowledge over time.
Claude Code is now generally available, integrating Claude into development workflows with support for background tasks via GitHub Actions and native integrations with VS Code and JetBrains. This allows edits to appear inline in files for seamless pair programming.
New API capabilities include the code execution tool, MCP connector, Files API, and prompt caching for up to one hour, enabling developers to build more powerful AI agents.
Model Availability and Pricing
Claude Opus 4 and Sonnet 4 are hybrid models offering two modes: near-instant responses and extended thinking for deeper reasoning. They are available on the Anthropic API, Amazon Bedrock, and Google Cloud's Vertex AI. Pricing remains consistent with previous models: Opus 4 at $15/$75 per million tokens (input/output) and Sonnet 4 at $3/$15. Sonnet 4 is also available to free users.
Claude Opus 4 Performance
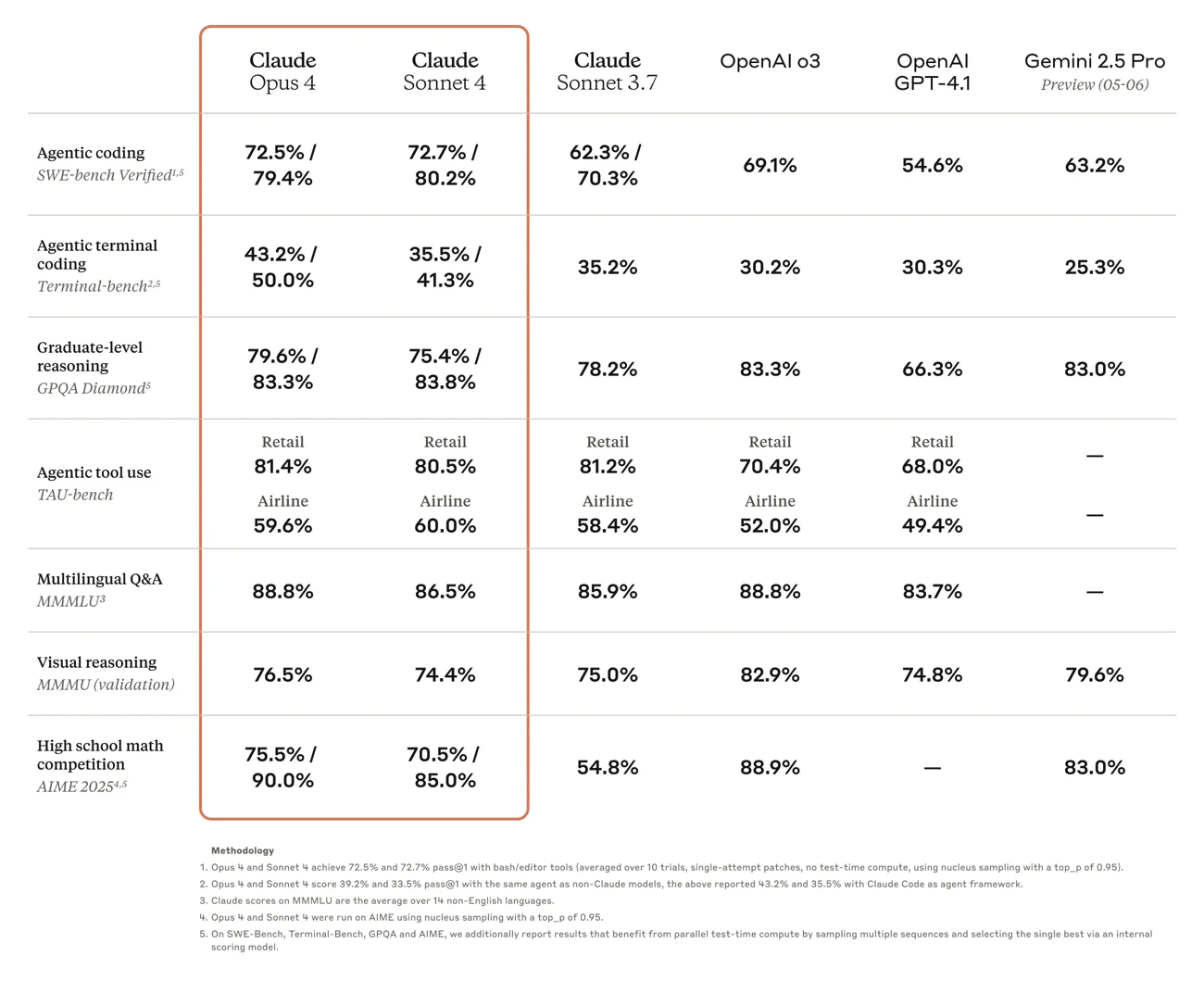
Claude Opus 4 leads on SWE-bench (72.5%) and Terminal-bench (43.2%), delivering sustained performance on tasks requiring thousands of steps over several hours. It excels in coding and complex problem-solving, powering frontier agent products. Industry feedback highlights its state-of-the-art coding abilities, improved precision, and reliability during editing and debugging. It has been validated in demanding scenarios, such as a 7-hour independent open-source refactor, and excels at solving complex challenges missed by previous models.
Claude Sonnet 4 Performance
Claude Sonnet 4 improves on Sonnet 3.7 with a 72.7% score on SWE-bench, balancing performance and efficiency for various use cases. It offers enhanced steerability for better control and is praised for following complex instructions, clear reasoning, and producing aesthetic outputs. It excels in autonomous multi-feature app development, significantly reduces navigation errors, and is recognized as a substantial leap in software development quality. It will power the new coding agent in GitHub Copilot.
Model Improvements
Both models have reduced tendencies to use shortcuts or loopholes by 65% compared to Sonnet 3.7 on agentic tasks. Claude Opus 4 notably outperforms previous models in memory capabilities, creating and maintaining "memory files" when given local file access, which enhances long-term task awareness and coherence. For example, it can create a "Navigation Guide" while playing Pokémon, recording key information to improve gameplay.
A new feature, thinking summaries, uses a smaller model to condense lengthy thought processes, needed only about 5% of the time. Advanced users can access full raw chains of thought via a Developer Mode.
Claude Code Integration
Claude Code extends Claude’s power to development workflows, available in terminals, IDEs (VS Code and JetBrains), and background tasks via the Claude Code SDK. Inline proposed edits streamline review and tracking. The SDK allows building custom agents and applications, with an example being Claude Code on GitHub (beta), which can respond to PR feedback, fix CI errors, or modify code.
Safety and Future Outlook
These models represent a significant step toward a virtual collaborator capable of maintaining full context and focus on longer projects, driving transformational impact. They have undergone extensive testing to minimize risk and maximize safety, including compliance with higher AI Safety Levels like ASL-3.
Claude 4 models push boundaries in coding, research, writing, and scientific discovery, while Sonnet 4 enhances everyday use cases with frontier performance, marking a major advancement in AI capabilities for developers and enterprises alike.